ML 분석환경
Jupyter
개요
Jupyter는 라이브 코드, 수식, 시각화, 텍스트 등이 포함된 문서를 만들고 공유할 수 있는 웹 기반의 대화형 IDE입니다. AIDP의 분석과 관련된 모든 기능을 제공하는 통합 EDA(Exploratory Data Analysis) 도구로 제공합니다.
온 프레미스 빅데이터 분석은 물론 클라우드 분석 서비스를 사용할 수 있으며, 딥러닝을 위해 GPU도 지원하고 있습니다.
- 빅데이터 분석 (YE) : HDFS, Hive, Spark2
- 클라우드 분석 : GCP GCS, BigQuery
- 딥 러닝 : Nvidia GPU 지원
구조
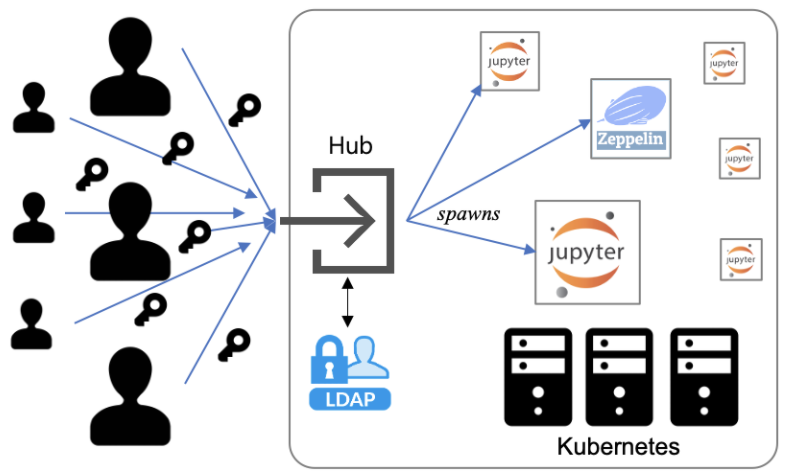
AIDP의 Jupyter는 쿠버네티스 환경에 구축되었습니다. SKTML 계정으로 인증을 받은 사용자는 원하는 기능과 자원을 선택한 후 Jupyter 컨테이너를 할당 받게 됩니다. 사용자 데이터와 분석 결과는 클라우드 저장소에 보관되며 다른 사용자들과 공유할 수 있습니다. 사용자 컨테이너는 자동으로 업데이트 되어 항상 최신으로 유지됩니다.
접속하기
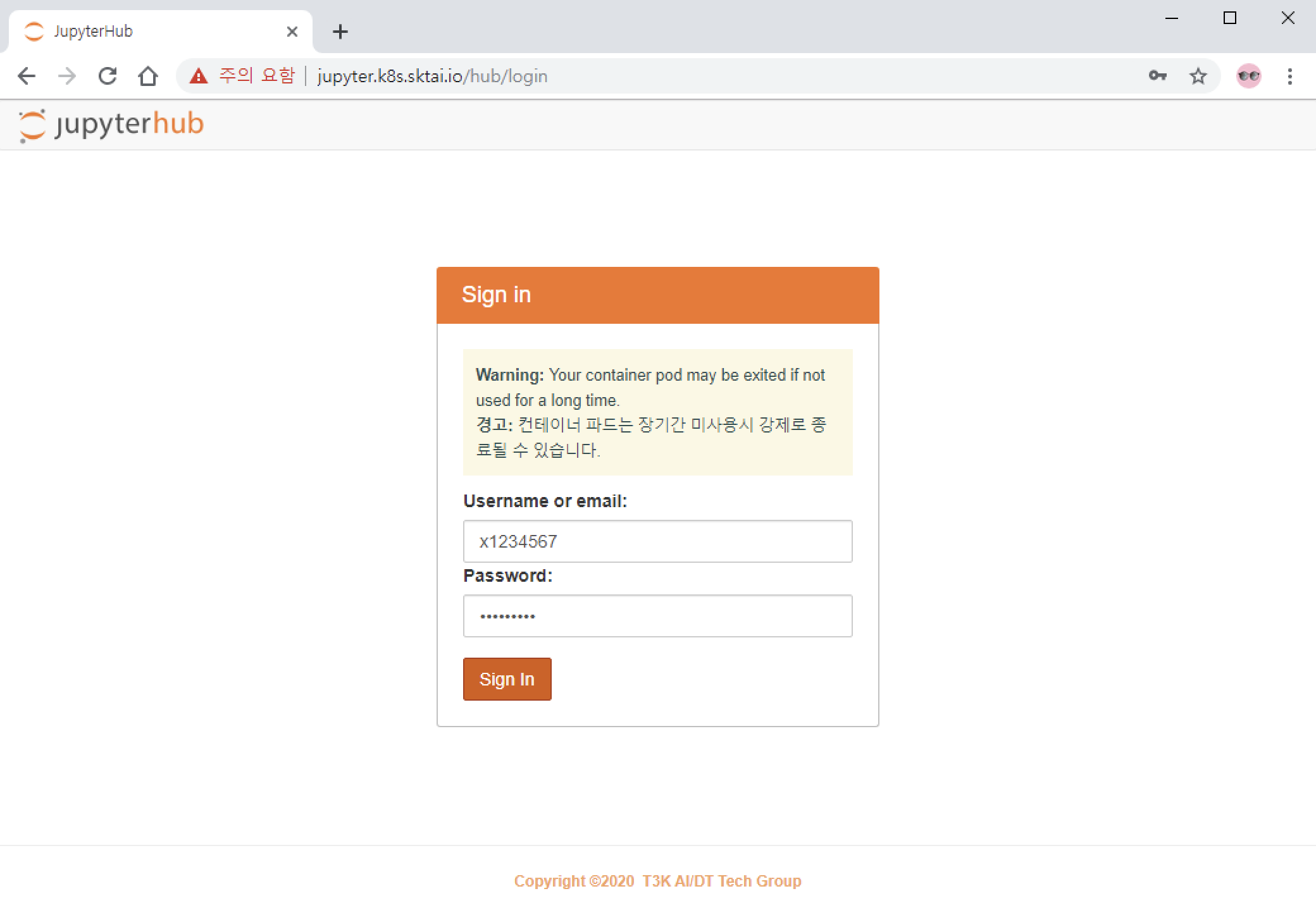
Jupyter에 접속하기 위해서는 사용자 VDI와 SKTML 계정이 필요합니다. VDI 환경에서 웹브라우저를 실행한 후 Jupyter 서비스 URL로 접근합니다.
- URL :
http://jupyter.k8s.sktai.io
SKTML 계정으로 로그인 합니다. 계정명 또는 이메일로 로그인 할 수 있습니다.
x1234567/x1234567@sktml.ioorrobin@sk.com
노트북 스택
처음으로 접속한 경우, 사용자에게 맞는 노트북 스택을 선택해야 합니다. 총 5개의 노트북 스택이 제공되며, 대부분의 분석 작업은 Basic 스택을 사용하여 할 수 있습니다.
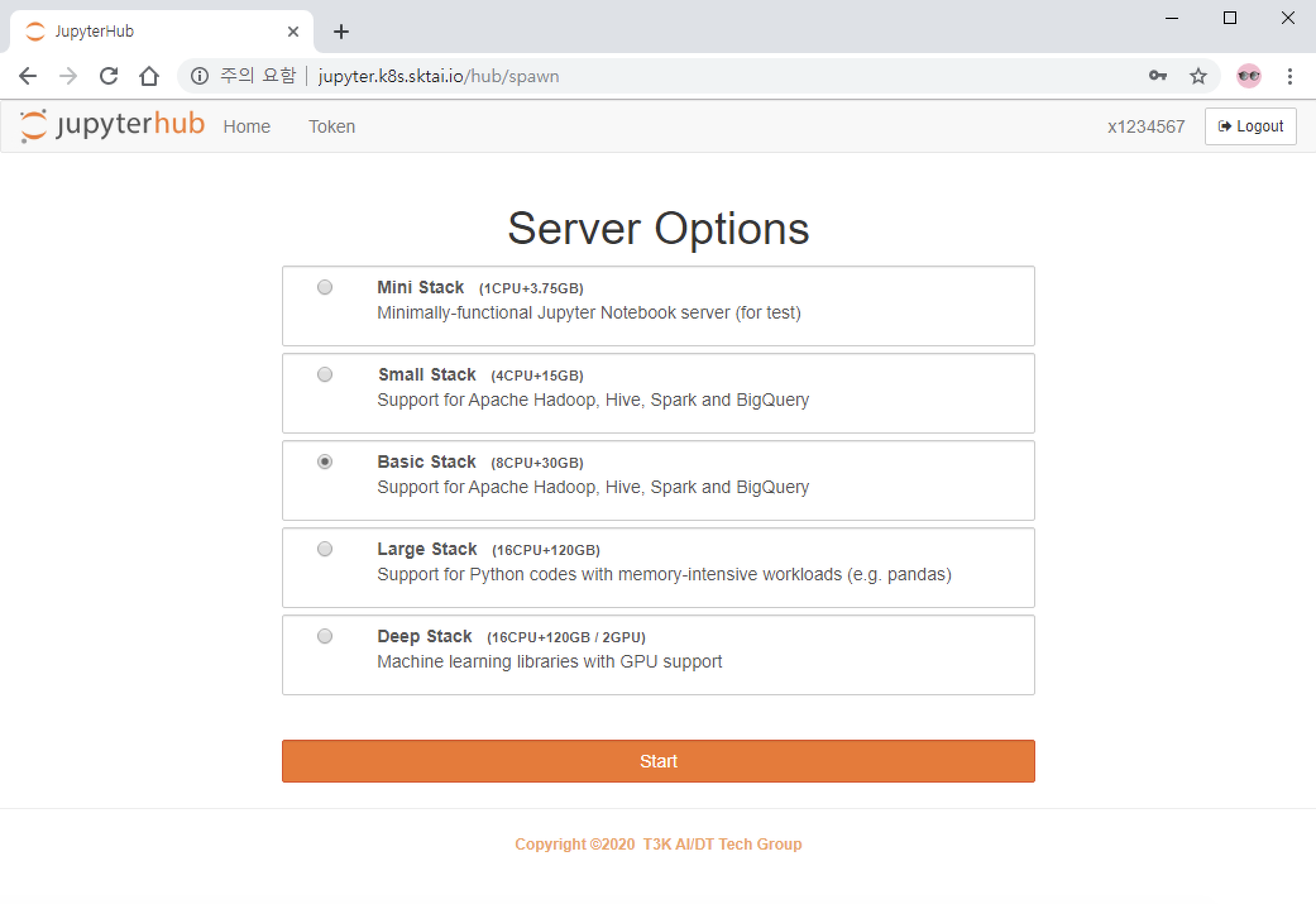
상위 스택을 선택할 수록 더 많은 자원을 할당 받을 수 있지만, 미사용시 자원이 회수되는 시간이 빨라집니다. Basic 스택을 선택하면 주중에는 자원이 회수되지 않게 됩니다.
| 노트북 스택 | 할당 자원 | 회수 기준 (미사용) |
|---|---|---|
| Mini | 1 CPU / 3.75G RAM | 14일 |
| Small | 4 CPU / 15G RAM | 3일 |
| Basic | 8 CPU / 30G RAM | 18시간 |
| Large | 16 CPU / 120G RAM | 6시간 |
| Deep | 16 CPU / 120G RAM / 2 GPU | 6시간 |
노트북 스택을 선택한 후 "Start" 버튼을 클릭하면 컨테이너 생성이 진행됩니다. 실시간으로 진행 상태가 업데이트 됩니다. 상황에 따라 최대 5~10분 까지 시간이 걸릴 수 있습니다.
홈 화면
컨테이너가 성공적으로 만들어지면 브라우저에 홈 화면이 표시됩니다. 홈 화면은 다음과 같이 구성됩니다.
- 상단 메뉴 바
- 좌측 사이드 바
- 주 작업 영역
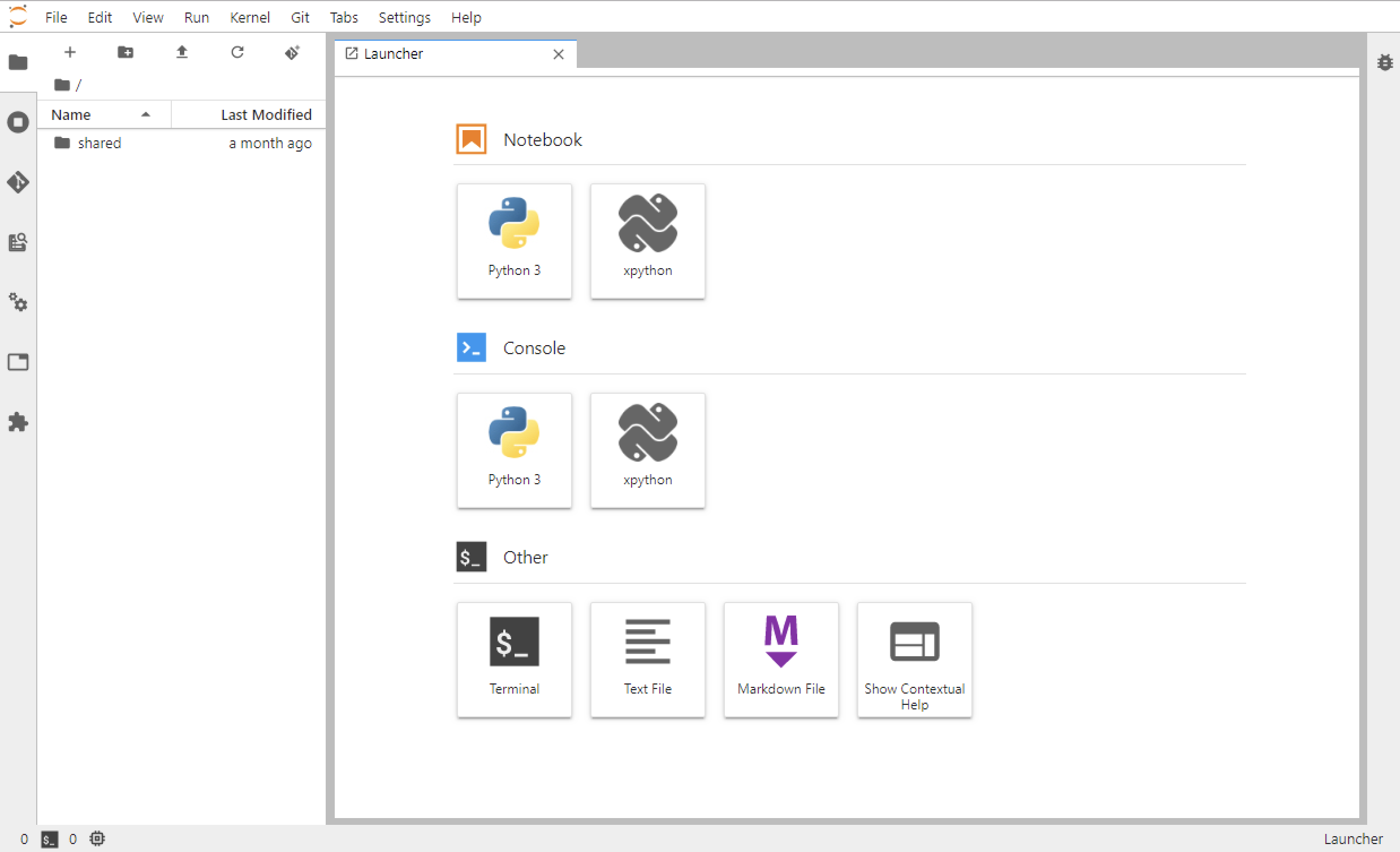
상단 메뉴 바
메뉴 바에서는 나의 컨테이너를 관리하고, 화면 스타일을 설정할 수 있습니다.
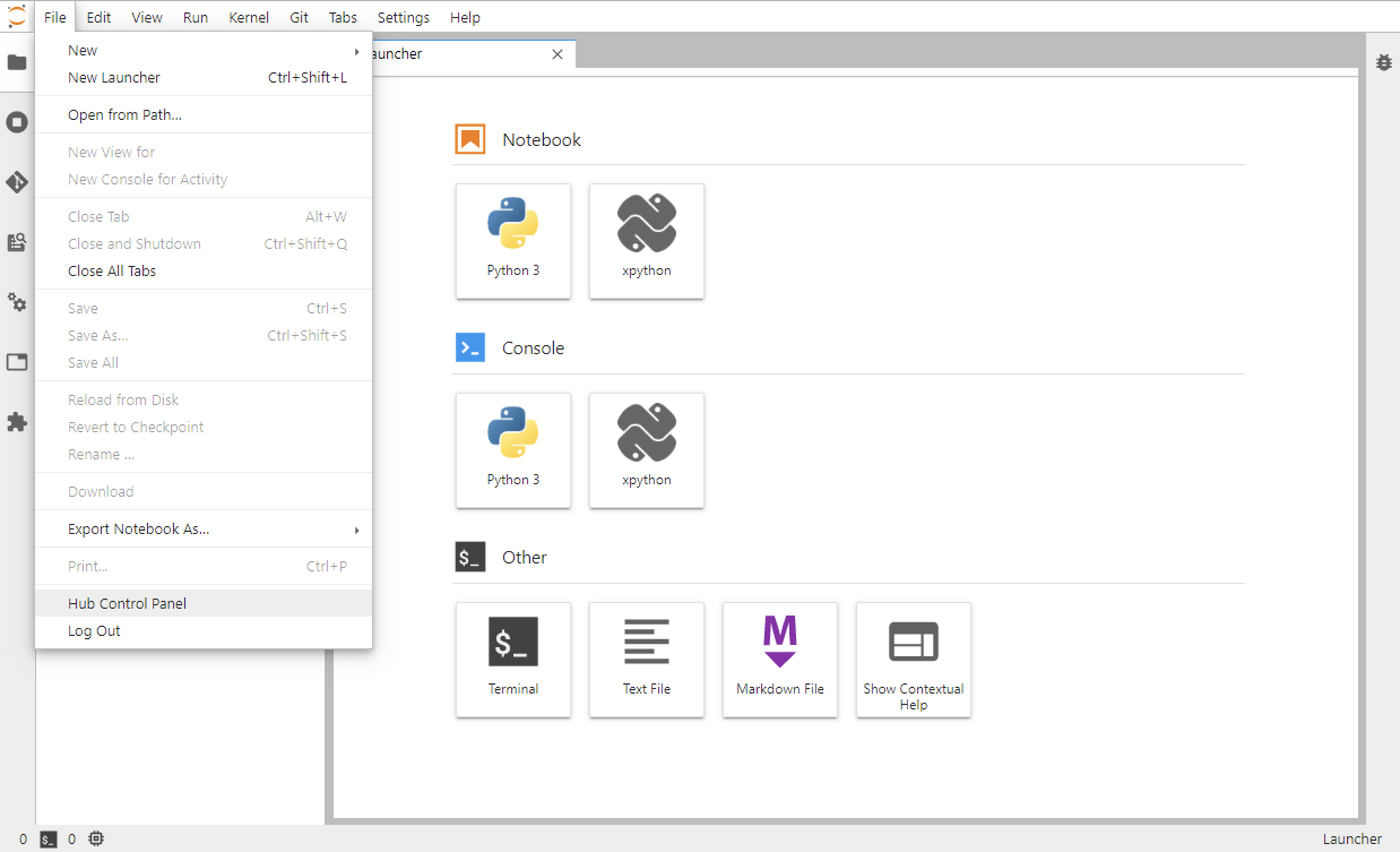
제어판에 들어가면 노트북 컨테이너를 새로 만들 수 있습니다. 새로운 스택으로 변경 하거나 노트북 기능 패치나 업데이트 할 때 유용합니다.
File > Hub Control Panel > Home
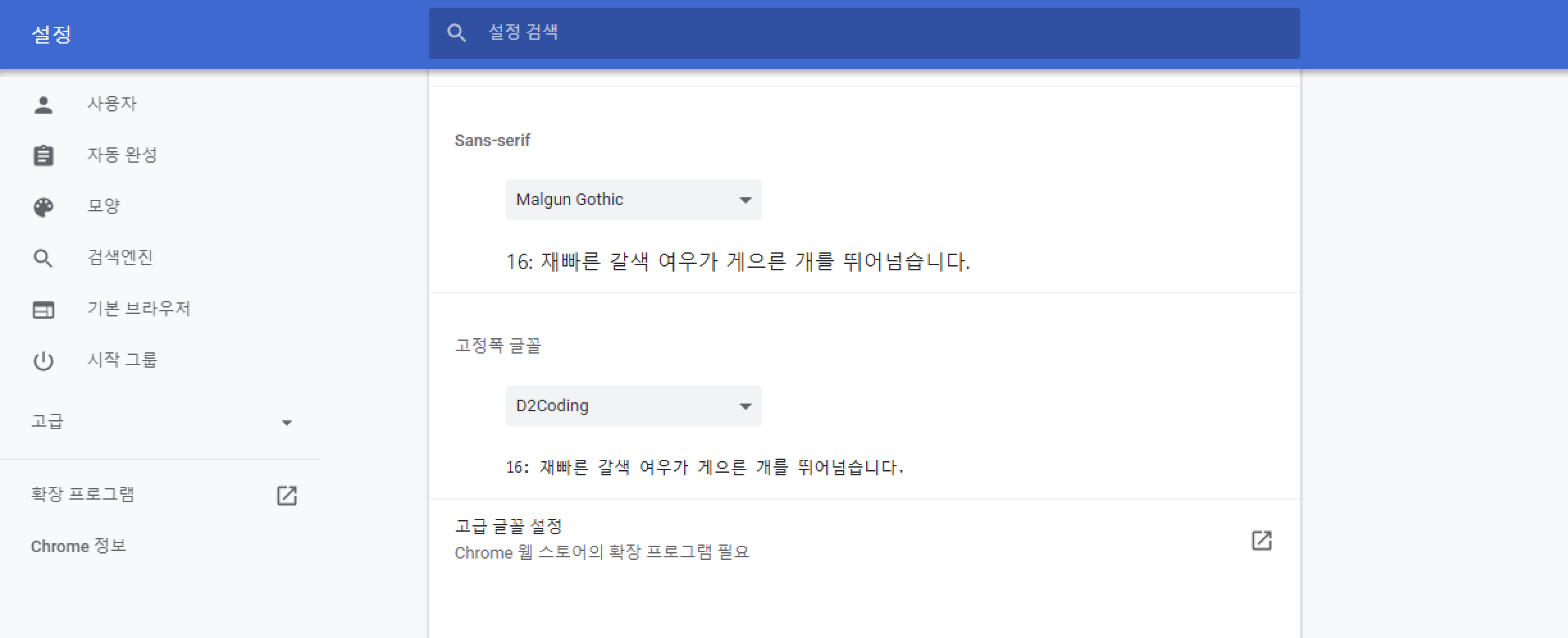
브라우저 폰트를 변경하면 좀 더 가독성이 높은 환경에서 작업을 할 수 있습니다.
설정 > 모양 > 글꼴 맞춤설정 > 고정폭 글꼴
- 권장 폰트 : NHN D2Coding
http://repo.sktai.io/tools/font/D2Coding-Ver1.3.2-20180524-all.ttc
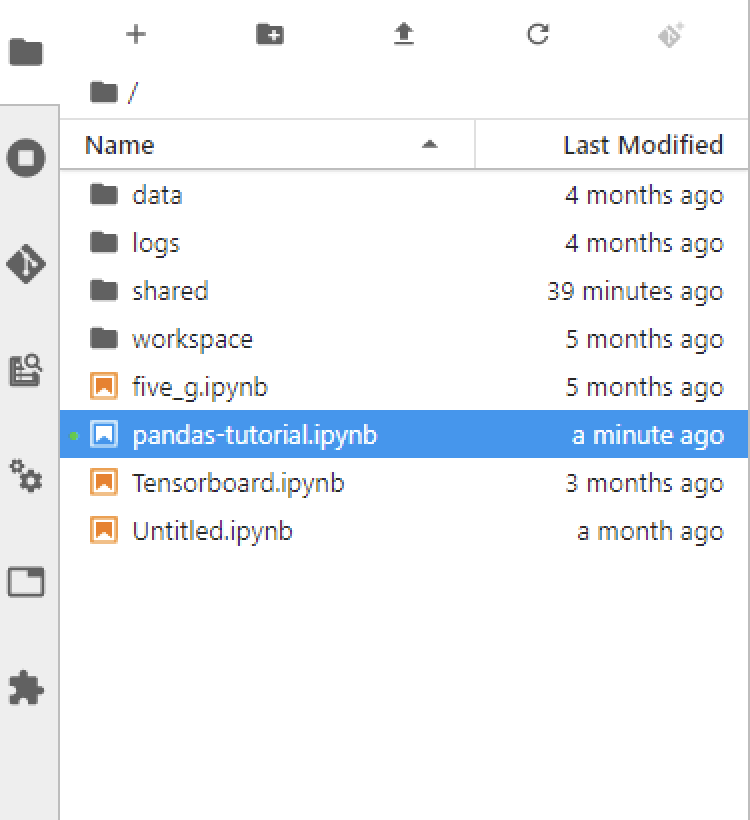
좌측 사이드 바
사이드 바는 파일 목록이나 세션, 탭, 노트북 등의 개체에 대한 요약 정보를 보여줍니다. 파일을 관리하고 여러 개체를 삭제하거나 종료할 수 있습니다.
주 작업 영역
주 작업 영역에서는 노트북이나 터미널을 실행하여 대화형으로 작업을 할 수 있습니다. 또, 시각화된 결과도 볼 수 있습니다.
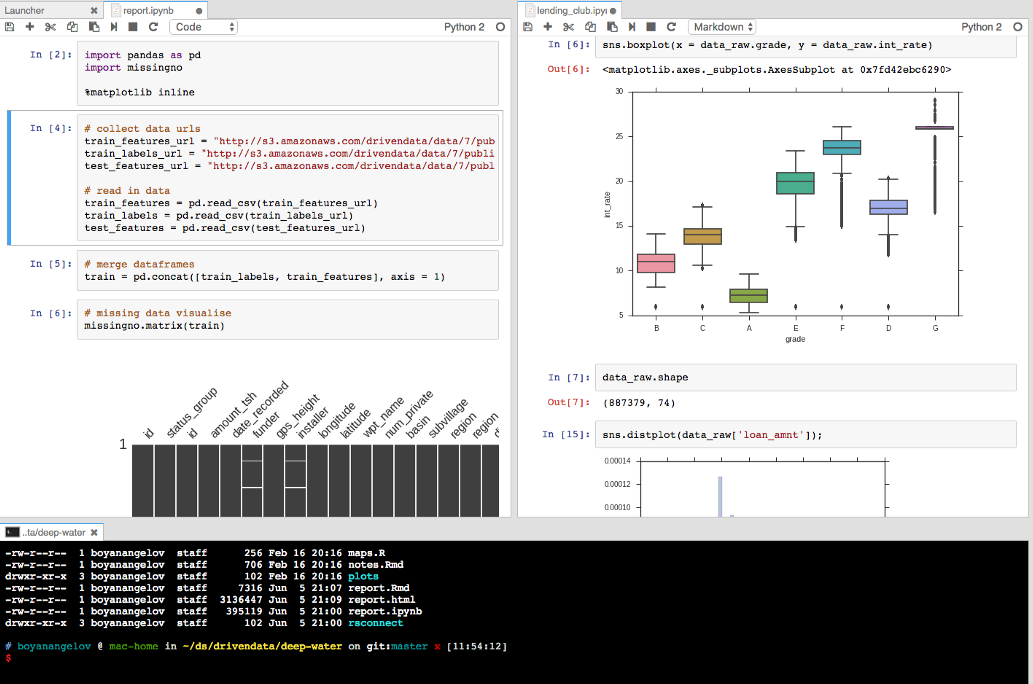
분석하기
기본 분석
AIDP는 사용자가 데이터 분석과 모델링에 집중할 수 있도록 온 프레미스와 클라우드 데이터 소스와 분석 도구를 추상화한 파이썬 패키지를 기본적으로 제공합니다.
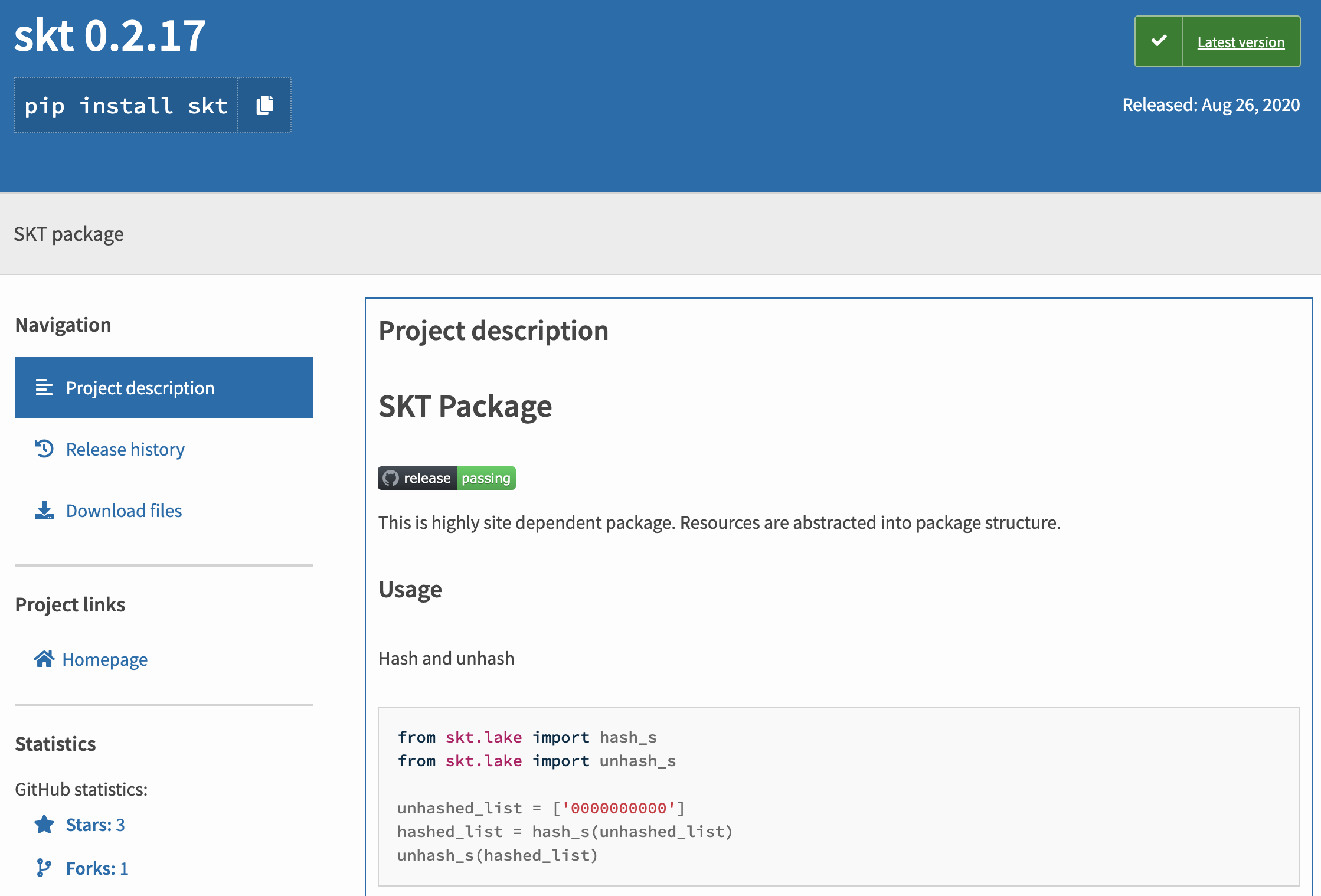
skt 패키지를 사용하면 하이브리드 분석 환경에서 데이터 분석을 쉽게 할 수 있습니다. 현재 아래와 같은 기능을 제공하며, 지속적으로 그 기능이 확장되고 있습니다.
- 개인정보 해싱/역해싱
- 온 프레미스 Hive SQL
- 온 프레미스 Spark SQL
- GCP BigQuery
- MLS 모델 서빙
패키지 공식 사이트를 참고하여 따라하면 쉽게 사용할 수 있습니다.
고급 분석
터미널을 사용하면 CLI 도구들를 사용해서 사용자가 원하는 대로 고급 분석을 할 수 있습니다.
❙ HDFS
$ hdfs dfs
Usage: hadoop fs [generic options]
[-cat [-ignoreCrc] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
...
❙ Hive (Beeline)
$ bee
Beeline version 3.1.0.3.0.1.0-187 by Apache Hive
0: jdbc:hive2://ye.sktai.io:20000/default> show tables;
+--------------------------------------+
| tab_name |
+--------------------------------------+
| mytable |
| sample |
| user_profile_pivot |
| ... |
+--------------------------------------+
11 rows selected (0.119 seconds)
0: jdbc:hive2://ye.sktai.io:20000/default>
❙ Spark2
$ spark-shell
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.1.3.0.1.0-187
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_265)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
❙ PySpark2
$ pyspark
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.3.1.3.0.1.0-187
/_/
Using Python version 3.6.10 (default, Apr 24 2020 16:44:11)
SparkSession available as 'spark'.
>>>