Data Delivery (ETL)
목차
Terminology
-
YE: Yellow Elephant의 줄일말로 On-premise Cluster를 의미합니다
- YE는 DW인 Hive, 통합 분석환경인 JupyterHub, Serverless Jupyter Notebook 실행 서비스인 NES 등이 동작하고 있습니다.
- Saturn: YE Hive DB로, DataLake쪽에서 오는 모든 원천 데이터를 담고 있습니다
-
Comm: YE Hive DB로, 분석에 편하게 활용 할수 있게 Saturn을 가공해 적재하고 있습니다
-
보통 분석 동의 필터 적용 또는 최신 Snapshot 유지 용도로 테이블들이 적재됩니다
- GCP: Google Cloud Platform로, Saturn에서 올라가는 모든 데이터는 1차적으로 GCP BigQuery에 적재됩니다
- NES: Notebook Execution Service의 약어로 Jupyter Notebook 링크와 패러미터를 주면 실행해주는 서비스입니다
- Airflow NESOperator를 활용한다면 Notebook을 최소한의 노력으로 Scheduled Task로 바꿀 수 있습니다
- AIM내 NES Worflow 화면에서 으로 Notebook → DAG로 변환할 수 있습니다
Data Ingestion
- 기본적으로 모든 테이블은 Saturn에 1차적으로 적재됩니다
- 새 테이블의 정기연동 요청은 매주 목요일(DataLake 정기 배포 일) 됩니다
- 테이블이 빨리 필요한 경우에는 Data Management팀의 김수겸님께 요청하시면 받아보실 수 있습니다
- 필요에 따라 GCP 또는 Comm 추가적재를 요청할 수 있습니다.
- 현재 적재 되고 있는 테이블은 AIM Data Catalog 화면 또는 YE Hive로 확인이 가능합니다
신규 테이블 연동요청
1. AIM Data Ingestions 화면 내 Request Table 탭에서 폼을 작성(데이터 소요부서 신청)
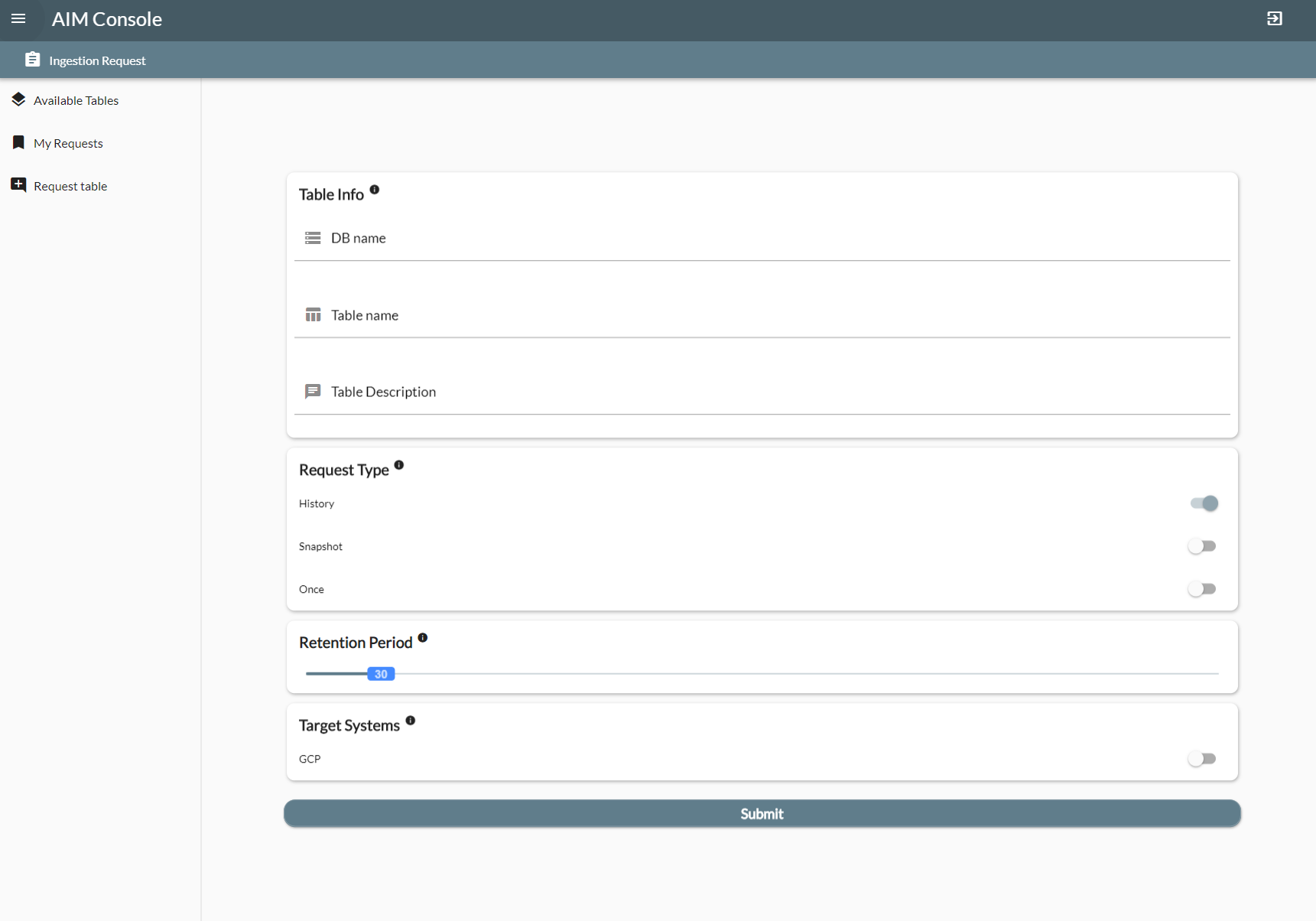
폼 작성 가이드
- 각 필드별 알맞은 값을 입력해주시면 됩니다
| 필드명 | 설명 |
|---|---|
| DB name | DataLake쪽 원천 database명 |
| Table name | 원천 테이블명 |
| Table description | 테이블에 대한 간략한 설명 |
| Request Type | 연동 유형 history: 증분 데이터를 매일 연동 snapshot : 전체 데이터를 매일 연동 once : 한번만 연동 |
| Retention Period | 최근 몇 일치만 유지 할지 |
| Target System | GCP BigQuery에 추가적으로 연동이 필요한 경우 체크 기본적으로 GCP 적재가 기본이며, 예외적으로 YE Comm적재 요청이 필요한 경우 별도 요청 필요 담당자: 최원준 (Bro), bro.ai@sktai.io |
2. Mydesk 內 Data Portal → DataGateway → 정기 연동 요청 작성. 요청하신 후 소속 조직 결재 권한을 가진 사람이 승인해야 Lake쪽에서도 착수합니다. (AIDP DE파트에서 일괄 신청)
- Data Lake는 정기 연동을 주 1회 반영하며, AIM을 통해 요청 된 데이터 연동 신청을 수합하여 AIDP DE파트에서 일괄 신청
3. 폼 작성 후 매일 신청한 테이블 상태를 #aidt-coe-airflow-noti slack채널에서 현황을 받아 보실 수 있습니다
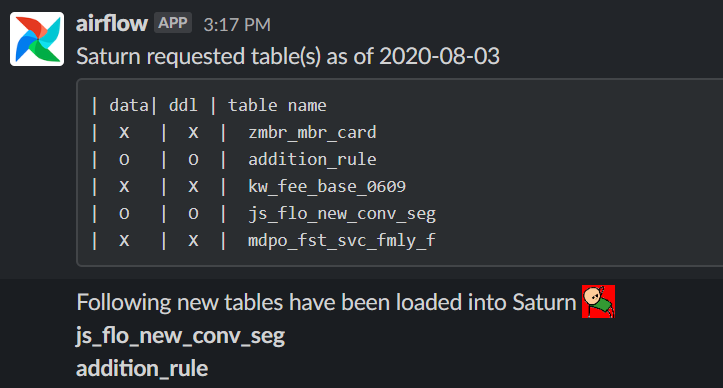
위 모습은 요청이 들어온 테이블 5건중, 2건이 유효한 파티션과 DDL이 적재된걸로 확인되 saturn에 테이블을 자동생성하는 모습입니다.
Data Tracking
-
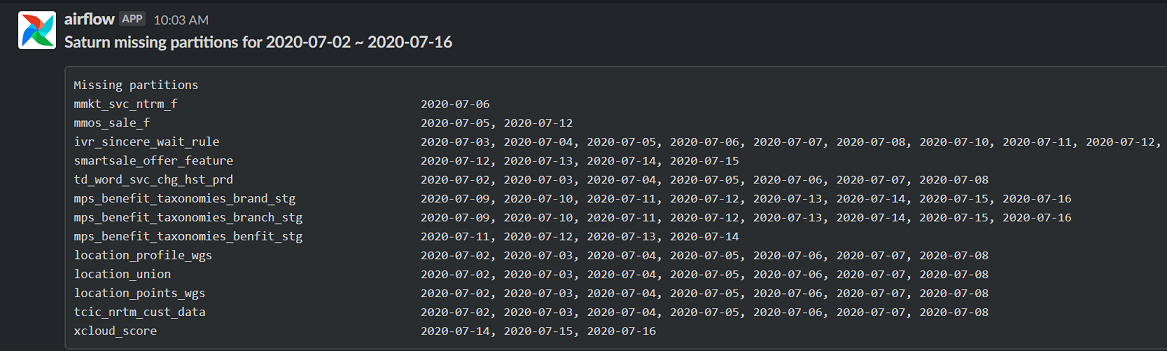
#aidt-coe-airflow-noti 채널에서 알림 금일 아직 적재 되지 않은 파티션 목록을 볼 수 있습니다
-
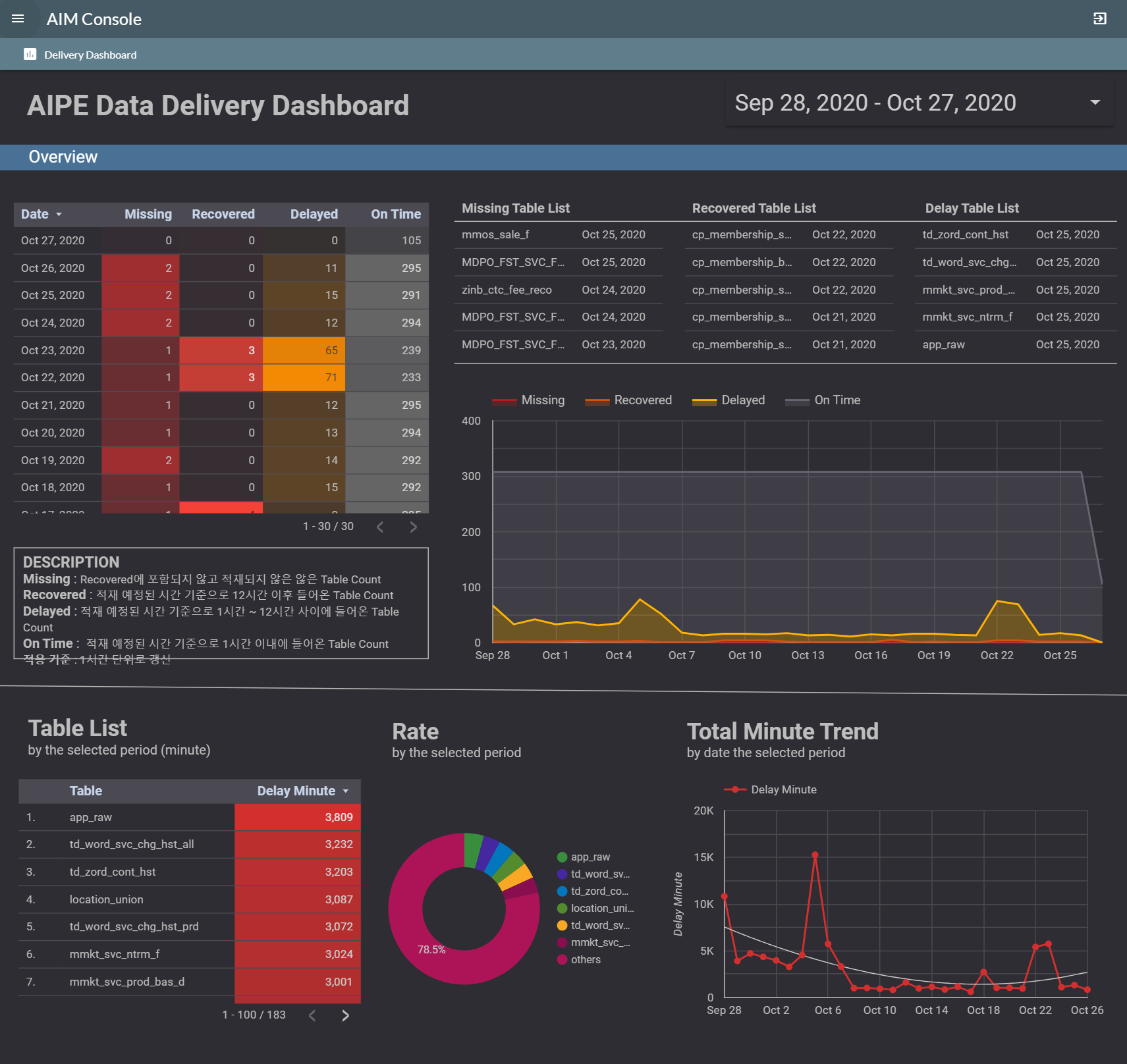
AIM Data Delivery Dashboard에서 더 자세하게 파악할 수 있습니다