Data catalog 가이드
Data catalog 개요
Data catalog는 YE Hive 및 Bigquery에서 관리하는 Table 및 Column 정보, database (bigquery의 경우 dataset) 정보, query 내역등을 수집 및 가공하여 사용자가 편리하게 검색할 수 있는 기능과, 다양한 사용자 관점에서의 편의 기능들을 제공해주는 것을 목표로 하는 프로젝트 입니다. 또, 주기적으로 datalake의 catalog 서비스인 Finddata의 정보를 연동받아 datalake의 table 및 column 정보들도 동일한 기준으로 검색하여 원하는 정보를 찾을 수 있습니다.
Data catalog 사용 방법
- SKT 패키지 사용 (권장)
- Python3 사용자에게 권장
- Data catalog REST API에서 제공하는 기능들을 사용자 입장에서 사용하게 편하도록 제작한 method들을 제공하는게 목적
- Data catalog client API 사용
- Python3를 사용하지 않는 경우
- REST API를 통해 Data catalog client API 서버에 접근 및 사용
- 사용자 편의가 아닌 API 측면에서 기능들을 관리하므로, 원하는 기능을 사용하기 위해서는 API에서 가져온 데이터를 사용자가 가공해야 하기에 Python3 사용 시 SKT 패키지 사용을 권장합니다.
Data catalog 예제
Data catalog와 같은 서비스는 내가 찾고자 하는 테이블이 있는지, 어떤 메타데이터를 가지고 있는지 검색해보는 간단한 검색 용도부터 저장된 데이터들을 활용하여 신규 사용자에게 도움을 주는 교육 용도로도 사용할 수 있습니다. 신규 사용자가 자신과 협업하는 사람들이 사용하고 있는 데이터 및 쿼리를 확인할 수 있다면 자신의 업무 범위 및 방식에 대해 빠르게 파악이 가능하고, 많은 사용자들이 사용하고 있는 데이터를 살펴볼 수 있다면 자신의 업무에 대한 확장에 관련된 많은 정보들을 얻을 수 있을 겁니다.
Data catalog는 지속적으로 개선 및 개발을 진행하고 있는 프로젝트로, 아래에서 대표로 소개하는 method들 외에도 여러 많은 기능들을 가지고 있습니다. 관련되어 자세한 사항들은 패키지 사용 제목에 있는 링크를 참조 부탁드립니다.
아래에 있는 예제들은 AIDP에서 제공하는 Jupyterhub 분석 환경에서 진행했으며, SKT 패키지, REST API 둘 다 Python3의 라이브러리 및 패키지들을 활용하여 작성하였습니다. REST API 예제의 경우 SKT 패키지에서 구현한 내용을 inline에서 다시 정의하여 사용하는 형식으로 진행합니다.
ID의 구조
Data catalog는 다양한 source들로부터 metadata들을 가져와야 해 독자적인 ID 체계를 만들어 사용하고 있습니다. 해당 ID 체계는 Apache Atlas 에 강하게 영향을 받았으며, Metadata 정의 페이지를 통해 왜, 그리고 어떻게 관리하고 있는지 정의하고 있습니다.
{database_name}.{table_name}.{column_name}@{cluster_name}
위와 같은 형식으로 ID (qualified_name)을 정의하여 사용하고 있습니다. 예를 들어, 아래의 예제에서 나오는 'ye_comm.user_profile_pivot_monthly@sktaic-datahub' ID는 'sktaic-datahub' cluster에 'ye_comm' dataset 안의 user_profile_pivot_monthly 이름을 갖는 table의 ID를 뜻합니다. 현재 data catalog에서 관리하는 cluster는 총 3가지로, 다음과 같습니다:
- sktaic-datahub
- GCP sktaic-datahub project 아래에 있는 Bigquery를 뜻합니다. 현재 해당 project만을 사용하고 있으므로 Bigquery에 있는 데이터라 생각하시면 됩니다.
- YELLOW_ELEPHANT
- TiDC내 AIDP에서 관리하는 Hadoop (Hive) cluster 입니다.
- Finddata
- Datalake에서 관리하는 finddata service에서 추출한 데이터들을 관리할 때 사용하는 cluster ID 입니다.
예제 1) 가장 많이 사용한 테이블
SKT 패키지 사용 - SKT 패키지에서 사용할 수 있는 method 목록
이 예제에서는 SKT 패키지에서 제공하는 함수를 통해 2020-07-01 ~ 2020-07-31 한달 간 분석 플랫폼에서 가장 많이 사용된 table 목록을 조회, table metadata를 확인하고, table을 사용한 query 를 살펴봐 실무에서 어떻게 사용하고 있는지 확인 한 뒤 해당 query의 결과 데이터를 재생산 해보는 예제 입니다.
data catalog import 및 사용
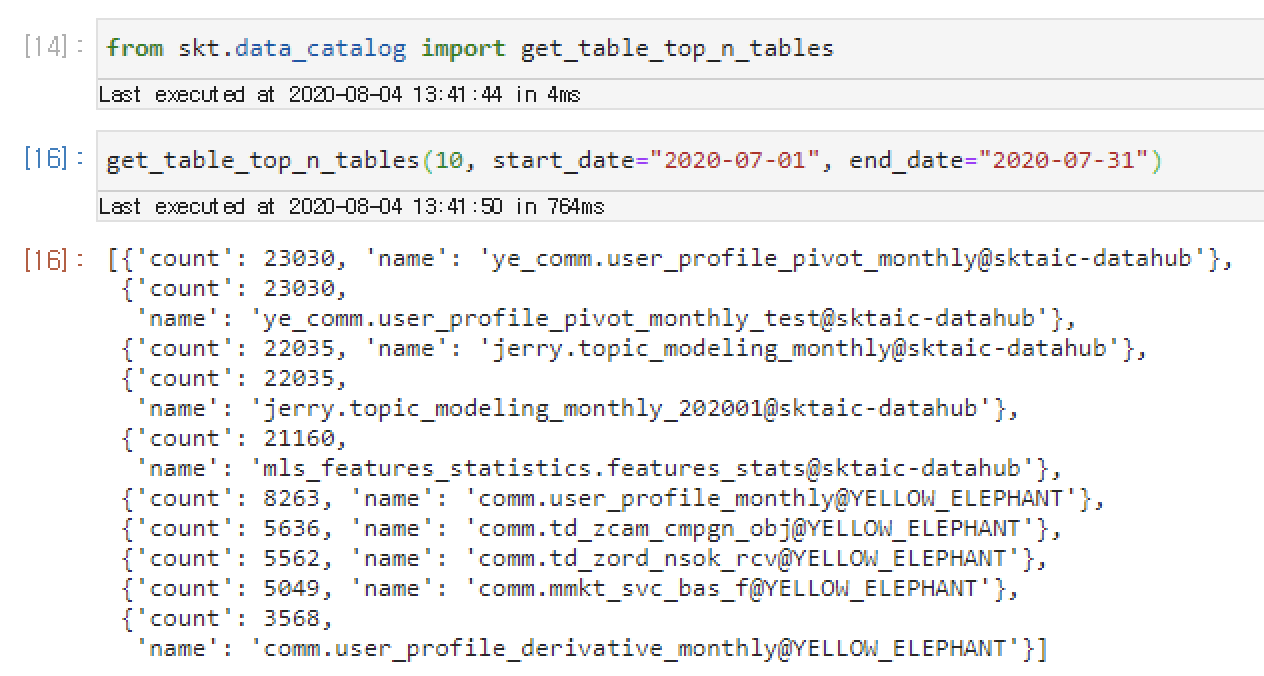
from skt.data_catalog import get_table_top_n_tables
get_table_top_n_tables(10, start_date="2020-07-01", end_date="2020-07-31")
위와 같이 SKT 패키지에서 제공하는 data catalog 관련 method들 중, get_table_top_n_tables method를 통하여 간단하게 항목을 가져올 수 있습니다. 예제 사진을 확인하면, 'ye_comm.user_profile_pivot_montthly@sktaic-datahub' table이 가장 많이 사용된 것을 확인할 수 있습니다.
data catalog table 조회
from skt.data_catalog import get_table
get_table('ye_comm.user_profile_pivot_montthly@sktaic-datahub')
조회된 table의 상세정보를 확인하고 싶으시면, get_table method 및 얻어 온 table_id를 사용해 table의 상세정보를 얻어올 수 있습니다.
번외) data catalog lineage 검색
분석 환경에서 접근할 수 있는 table들은 여러 가지 경로에서 수집 및 내보내고 있으며, data catalog에서는 가능한 이런 종류의 관계 데이터들 또 한 수집하려고 노력하고 있습니다. 관계 데이터들은 데이터 엔지니어에게는 side effect 최소화에 대한 hint를, 데이터 분석가들에게는 source 테이블 및 target 테이블을 확인함으로써 연관 관계가 있는 비즈니스 조직을 파악하는 등 각자의 업무에 맞춰 다양한 정보들을 얻을 수 있습니다.
from skt.data_catalog import get_lineage
get_lineage('ye_comm.user_profile_pivot_montthly@sktaic-datahub')
get_lineage method를 통해서 table과 직접적인 연관이 있는 테이블의 목록들을 가져올 수 있습니다.
data catalog table을 사용하는 query 조회
table의 상세정보를 통해 해당 table이 나에게 필요한 데이터 같다면, 실제로 어디서 사용되고 있는지, 어떤 방식으로 사용해야 하는지와 같이 활용할 수 있는 방법을 알아봐야 합니다. 이때, 이미 다른 사람이 사용한 query를 확인한다는 건 위 두 요건을 만족시킵니다. 아래와 같은 코드를 통해, 특정 테이블을 사용했던 query 내역들을 간단하게 불러올 수 있습니다.
from skt.data_catalog import search_queries_by_table_id
search_queries_by_table_id('ye_comm.user_profile_pivot_montthly@sktaic-datahub')
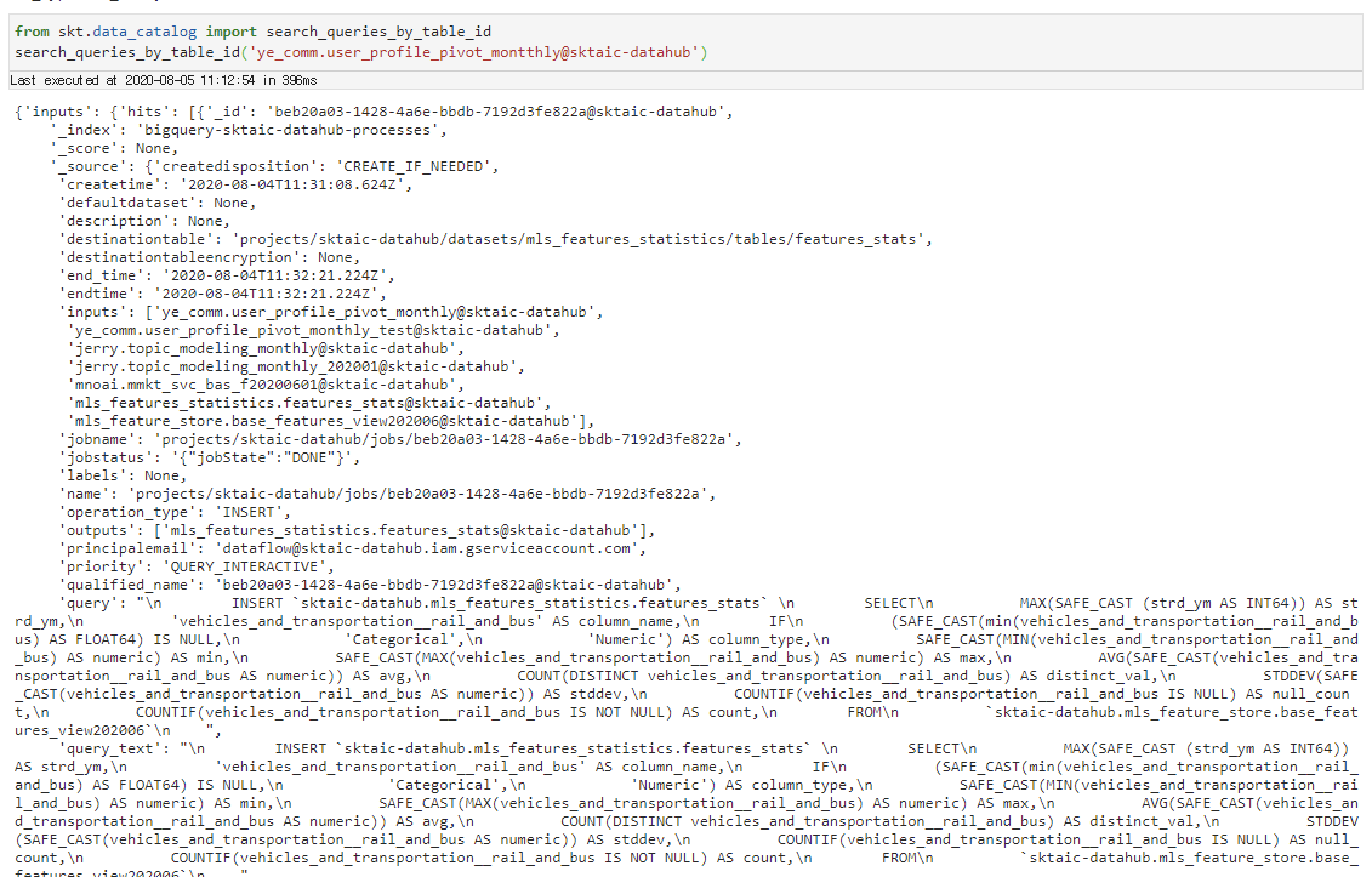
search_queries_by_table_id method는 directionary를 반환하며, inputs, outputs 각각의 key를 통해 해당 table이 어떠한 용도로 사용됐는지를 구분합니다.
REST API 사용 - Client API Swagger
HTTP 통신을 위해 requests, json parsing을 위해 json 을 사용하며, 두 개의 library는 미리 import 한 걸 가정합니다. Client REST API의 URL은 http://datacatalogsvc.sktai.io , Lineage REST API의 URL은 http://datalineage.sktai.io 입니다.
아래의 코드들은 REST API 활용에 대한 예시이므로, 실제 SKT 패키지에서의 구현과는 다를 수 있습니다.
data catalog import 및 사용
def get_table_top_n_tables(n, start_date=None, end_date=None):
params = {"top_n": n, "start_date": start_date, "end_date": end_date}
response = requests.get(lineage_url + "/relationships/queries/top_n/tables", params=params).json()
return response
get_table_top_n_tables(10, start_date="2020-07-01", end_date="2020-07-31")
data catalog table 조회
def get_table(table_id):
return requests.get(client_url + f"/v1/resources/tables/{table_id}").json()
get_table('ye_comm.user_profile_pivot_montthly@sktaic-datahub')
번외) data catalog lineage 검색
def get_lineage(table_id):
return requests.get(lineage_url + f"/relationships/lineage/node/{table_id}").json()
get_lineage('ye_comm.user_profile_pivot_montthly@sktaic-datahub')
data catalog table을 사용하는 query 조회
def search_queries_by_table_id(table_id, **kwargs):
es_sort = [{"start_time": "desc"}]
params = {
"inputs": table_id,
"outputs": table_id,
"sort": json.dumps(es_sort),
}
return requests.get(client_url + "/v1/search/processes", params=params).json()
search_queries_by_table_id('ye_comm.user_profile_pivot_montthly@sktaic-datahub')
예제 2) 특정 사용자가 사용한 테이블
SKT 패키지 사용 - SKT 패키지에서 사용할 수 있는 method 목록
data catalog import 및 사용
get_user_queries method를 통해 사용자가 실행한 query 목록을 가져오거나, get_user_data_access method를 통해 사용한 table 및 column 목록만을 따로 가져올 수 있습니다. 아래 예제는 해당 method들을 통해 2020-07-01 ~ 2020-07-31 한 달 간의 query 목록 및 table, column 접근 내역을 가져옵니다.
from skt.data_catalog import get_user_queries, get_user_data_access
# query 목록
get_user_queries('metsmania', '2020-07-01', '2020-07-31')
# 접근한 table 및 column 목록
get_user_data_access('metsmania', '2020-07-01', '2020-07-31')
REST API 사용 - Client API Swagger
data catalog import 및 사용
(공통) AIDP 분석환경에서 BigQuery 사용, 조회된 query 결과 확인하기
AIDP 분석환경 (Jupyter, RStudio, Zeppelin)에서는 로그인 한 사용자로 GCP 인증을 활성화 시켜놓아 별도의 인증 절차 없이 Bigquery 접근이 가능합니다. 여기서는 대표적으로 BigQuery Sample Notebook 을 통하여 Jupyter 환경에서 Bigquery 사용을 가정합니다.
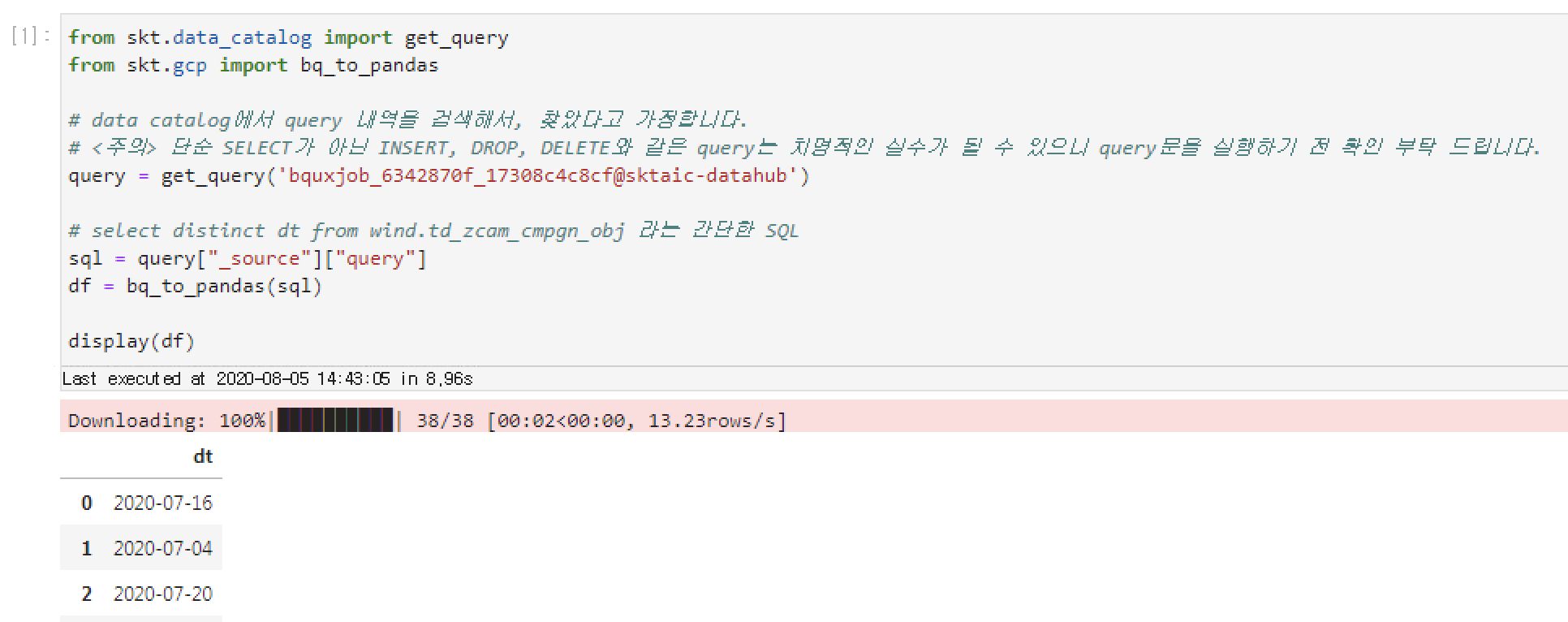
이 예제에서는 위의 예제 과정을 통해 특정 Bigquery query문을 얻었다고 가정합니다. 테스트를 위해, 'bquxjob_6342870f_17308c4c8cf@sktaic-datahub' ID를 갖는 query를 사용해 실행해 보겠습니다. query id를 통해서 query 내역을 불러온 후, 해당 query를 bigquery에서 실행합니다:
from skt.data_catalog import get_query
from skt.gcp import bq_to_pandas
# data catalog에서 query 내역을 검색해서, 찾았다고 가정합니다.
# <주의> 단순 SELECT가 아닌 INSERT, DROP, DELETE와 같은 query는 치명적인 실수가 될 수 있으니 query문을 실행하기 전 확인 부탁 드립니다.
query = get_query('bquxjob_6342870f_17308c4c8cf@sktaic-datahub')
# select distinct dt from wind.td_zcam_cmpgn_obj 라는 간단한 SQL
sql = query["_source"]["query"]
df = bq_to_pandas(sql)
display(df)